That would indeed be way (quadratically) more likely but we don’t count the number of attempts but measure run time, and since comparisons (even with optimizations like insertion sort) take time, the speed difference between the two methods will be “just” a few orders of magnitude.
As long as you don’t run out of memory, you can actually insert and lookup in O(1) time for a known space of values (that we have). Therefore we do get the quadratic speedup, that when dealing with bits of keysize or entropy means cutting it in half.
Checking to get a specific uuid takes 128bit, so 2128 draws of a uuid. Putting all previous uuids into a table we expect a collision in 64bit, so 264. We also need about that much storage to contain the table, so some tens of exabytes.

{kind=link}
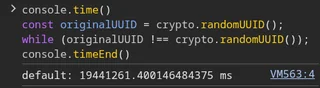
Only 5.4 hours before you hit a UUID collision. That’s insane
This is how we find out that crypto.randomUUID is not cryptographically secure
Aren’t UUIDs designed to prevent collisions, rather than be cryptographycally secure? Not that it’s doing a great job here :D
Edit: Nvm, that was guid.
Against a apecific one too. Usually you’d check for duplicates against all previous uuids
That would indeed be way (quadratically) more likely but we don’t count the number of attempts but measure run time, and since comparisons (even with optimizations like insertion sort) take time, the speed difference between the two methods will be “just” a few orders of magnitude.
As long as you don’t run out of memory, you can actually insert and lookup in O(1) time for a known space of values (that we have). Therefore we do get the quadratic speedup, that when dealing with bits of keysize or entropy means cutting it in half.
Checking to get a specific uuid takes 128bit, so 2128 draws of a uuid. Putting all previous uuids into a table we expect a collision in 64bit, so 264. We also need about that much storage to contain the table, so some tens of exabytes.