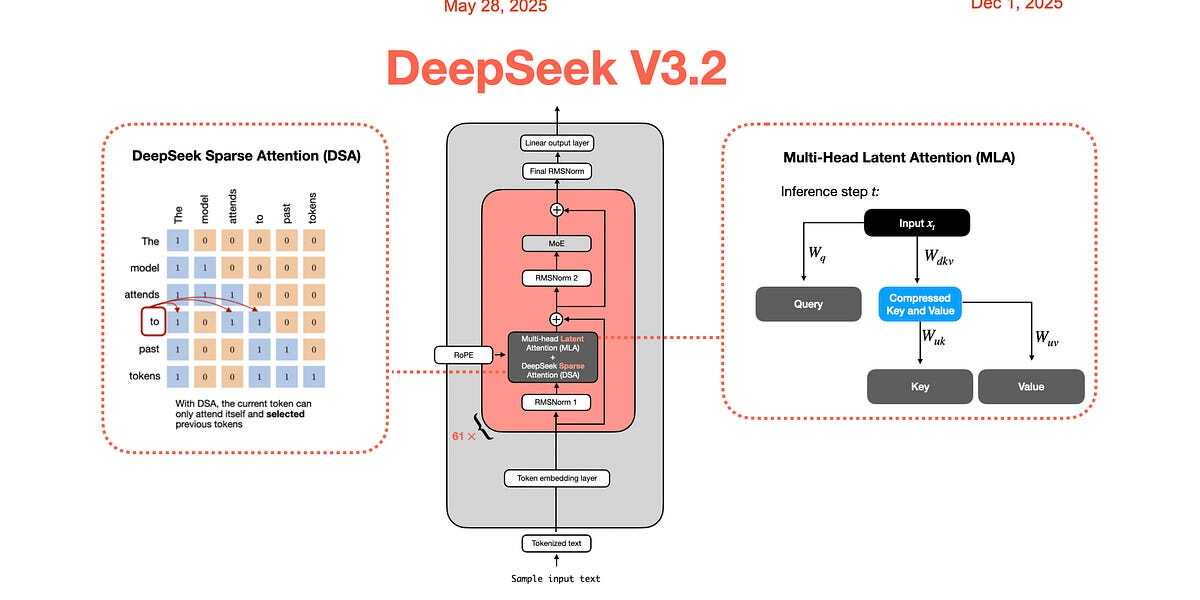
Note that this does assume some prior transformer architecture knowledge, but if you know how attention works then you should at least be able to get the overall idea. Comments
You must log in or register to comment.
Note that this does assume some prior transformer architecture knowledge, but if you know how attention works then you should at least be able to get the overall idea. Comments