I think ultimately copying the data would require having as many hard drives as the entire internet, but repeated queries only requires live bandwidth and minimal storage. One costs OpenAI more, one costs everyone else more.
The “entire internet” is not even that big these days. The Internet Archive, for instance, is on the order of 100s of petabytes. 10K (or at least less than 100K) spinning disks is almost trivial for Azure, who has many millions deployed.
And the actual training runs for text models are in the trillions of tokens; again, chump change data wise.
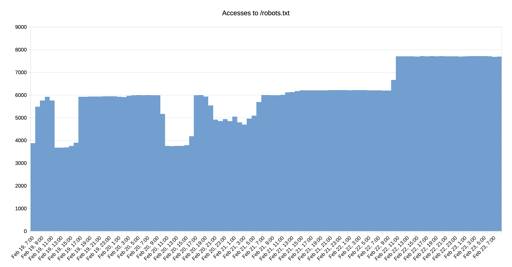
On the other hand, they’d lose a ton of ephemeral data scraping for training runs every time instead of just saving the good stuff. I suppose it’s possible they mass rescrape and filter the content redundantly, but… that seems like a colossal waste?
I think ultimately copying the data would require having as many hard drives as the entire internet, but repeated queries only requires live bandwidth and minimal storage. One costs OpenAI more, one costs everyone else more.
The “entire internet” is not even that big these days. The Internet Archive, for instance, is on the order of 100s of petabytes. 10K (or at least less than 100K) spinning disks is almost trivial for Azure, who has many millions deployed.
And the actual training runs for text models are in the trillions of tokens; again, chump change data wise.
On the other hand, they’d lose a ton of ephemeral data scraping for training runs every time instead of just saving the good stuff. I suppose it’s possible they mass rescrape and filter the content redundantly, but… that seems like a colossal waste?
Hmm, could be what they do, I guess.