

Those claiming AI training on copyrighted works is “theft” misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they’re extracting general patterns and concepts - the “Bob Dylan-ness” or “Hemingway-ness” - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in “vector space”. When generating new content, the AI isn’t recreating copyrighted works, but producing new expressions inspired by the concepts it’s learned.
This is fundamentally different from copying a book or song. It’s more like the long-standing artistic tradition of being influenced by others’ work. The law has always recognized that ideas themselves can’t be owned - only particular expressions of them.
Moreover, there’s precedent for this kind of use being considered “transformative” and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it’s understandable that creators feel uneasy about this new technology, labeling it “theft” is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn’t make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
If they can base their business on stealing, then we can steal their AI services, right?
Pirating isn’t stealing but yes the collective works of humanity should belong to humanity, not some slimy cabal of venture capitalists.
Also, ingredients to a recipe aren’t covered under copyright law.
ingredients to a recipe may well be subject to copyright, which is why food writers make sure their recipes are “unique” in some small way. Enough to make them different enough to avoid accusations of direct plagiarism.
E: removed unnecessary snark
In what country is that?
Under US law, you cannot copyright recipes. You can own a specific text in which you explain the recipe. But anyone can write down the same ingredients and instructions in a different way and own that text.
Keep in my that “ingredients to a recipe” here refers to the literal physical ingredients, based on the context of the OP (where a sandwich shop owner can’t afford to pay for their cheese).
While you can’t copyright a recipe, you can patent the ingredients themselves, especially if you had a hand in doing R&D to create it. See PepsiCo sues four Indian farmers for using its patented Lay’s potatoes.
No, you cannot patent an ingredient. What you can do - under Indian law - is get “protection” for a plant variety. In this case, a potato.
That law is called Protection of Plant Varieties and Farmers’ Rights Act, 2001. The farmer in this case being PepsiCo, which is how they successfully sued these 4 Indian farmers.
Farmers’ Rights for PepsiCo against farmers. Does that seem odd?
I’ve never met an intellectual property freak who didn’t lie through his teeth.
I think there is some confusion here between copyright and patent, similar in concept but legally exclusive. A person can copyright the order and selection of words used to express a recipe, but the recipe itself is not copy, it can however fall under patent law if proven to be unique enough, which is difficult to prove.
So you can technically own the patent to a recipe keeping other companies from selling the product of a recipe, however anyone can make the recipe themselves, if you can acquire it and not resell it. However that recipe can be expressed in many different ways, each having their own copyright.
Unlike regular piracy, accessing “their” product hosted on their servers using their power and compute is pretty clearly theft. Morally correct theft that I wholeheartedly support, but theft nonetheless.
Is that how this technology works? I’m not the most knowledgeable about tech stuff honestly (at least by Lemmy standards).
There’s self-hosted LLMs, (e.g. Ollama), but for the purposes of this conversation, yeah - they’re centrally hosted, compute intensive software services.
Yes, that’s exactly the point. It should belong to humanity, which means that anyone can use it to improve themselves. Or to create something nice for themselves or others. That’s exactly what AI companies are doing. And because it is not stealing, it is all still there for anyone else. Unless, of course, the copyrightists get there way.
How do you feel about Meta and Microsoft who do the same thing but publish their models open source for anyone to use?
Well how long to you think that’s going to last? They are for-profit companies after all.
I mean we’re having a discussion about what’s fair, my inherent implication is whether or not that would be a fair regulation to impose.
Those aren’t open source, neither by the OSI’s Open Source Definition nor by the OSI’s Open Source AI Definition.
The important part for the latter being a published listing of all the training data. (Trainers don’t have to provide the data, but they must provide at least a way to recreate the model given the same inputs).
Data information: Sufficiently detailed information about the data used to train the system, so that a skilled person can recreate a substantially equivalent system using the same or similar data. Data information shall be made available with licenses that comply with the Open Source Definition.
They are model-available if anything.
For the purposes of this conversation. That’s pretty much just a pedantic difference. They are paying to train those models and then providing them to the public to use completely freely in any way they want.
It would be like developing open source software and then not calling it open source because you didn’t publish the market research that guided your UX decisions.
You said open source. Open source is a type of licensure.
The entire point of licensure is legal pedantry.
And as far as your metaphor is concerned, pre-trained models are closer to pre-compiled binaries, which are expressly not considered Open Source according to the OSD.
You said open source. Open source is a type of licensure.
The entire point of licensure is legal pedantry.
No. Open source is a concept. That concept also has pedantic legal definitions, but the concept itself is not inherently pedantic.
And as far as your metaphor is concerned, pre-trained models are closer to pre-compiled binaries, which are expressly not considered Open Source according to the OSD.
No, they’re not. Which is why I didn’t use that metaphor.
A binary is explicitly a black box. There is nothing to learn from a binary, unless you explicitly decompile it back into source code.
In this case, literally all the source code is available. Any researcher can read through their model, learn from it, copy it, twist it, and build their own version of it wholesale. Not providing the training data, is more similar to saying that Yuzu or an emulator isn’t open source because it doesn’t provide copyrighted games. It is providing literally all of the parts of it that it can open source, and then letting the user feed it whatever training data they are allowed access to.
Tell me you’ve never compiled software from open source without saying you’ve never compiled software from open source.
The only differences between open source and freeware are pedantic, right guys?
Tell me you’ve never developed software without telling me you’ve never developed software.
A closed source binary that is copyrighted and illegal to use, is totally the same thing as a all the trained weights and underlying source code for a neural network published under the MIT license that anyone can learn from, copy, and use, however they want, right guys?
i feel like its less meaningful because we dont have access to the datasets.
Here’s an experiment for you to try at home. Ask an AI model a question, copy a sentence or two of what they give back, and paste it into a search engine. The results may surprise you.
And stop comparing AI to humans but then giving AI models more freedom. If I wrote a paper I’d need to cite my sources. Where the fuck are your sources ChatGPT? Oh right, we’re not allowed to see that but you can take whatever you want from us. Sounds fair.
The argument that these models learn in a way that’s similar to how humans do is absolutely false, and the idea that they discard their training data and produce new content is demonstrably incorrect. These models can and do regurgitate their training data, including copyrighted characters.
And these things don’t learn styles, techniques, or concepts. They effectively learn statistical averages and patterns and collage them together. I’ve gotten to the point where I can guess what model of image generator was used based on the same repeated mistakes that they make every time. Take a look at any generated image, and you won’t be able to identify where a light source is because the shadows come from all different directions. These things don’t understand the concept of a shadow or lighting, they just know that statistically lighter pixels are followed by darker pixels of the same hue and that some places have collections of lighter pixels. I recently heard about an ai that scientists had trained to identify pictures of wolves that was working with incredible accuracy. When they went in to figure out how it was identifying wolves from dogs like huskies so well, they found that it wasn’t even looking at the wolves at all. 100% of the images of wolves in its training data had snowy backgrounds, so it was simply searching for concentrations of white pixels (and therefore snow) in the image to determine whether or not a picture was of wolves or not.
The whole point of copyright in the first place, is to encourage creative expression, so we can have human culture and shit.
The idea of a “teensy” exception so that we can “advance” into a dark age of creative pointlessness and regurgitated slop, where humans doing the fun part has been made “unnecessary” by the unstoppable progress of “thinking” machines, would be hilarious, if it weren’t depressing as fuck.
I’ll train my AI on just the bee movie. Then I’m going to ask it “can you make me a movie about bees”? When it spits the whole movie, I can just watch it or sell it or whatever, it was a creation of my AI, which learned just like any human would! Of course I didn’t even pay for the original copy to train my AI, it’s for learning purposes, and learning should be a basic human right!
You drank the kool-aid.
The problem with your argument is that it is 100% possible to get ChatGPT to produce verbatim extracts of copyrighted works. This has been suppressed by OpenAI in a rather brute force kind of way, by prohibiting the prompts that have been found so far to do this (e.g. the infamous “poetry poetry poetry…” ad infinitum hack), but the possibility is still there, no matter how much they try to plaster over it. In fact there are some people, much smarter than me, who see technical similarities between compression technology and the process of training an LLM, calling it a “blurry JPEG of the Internet”… the point being, you wouldn’t allow distribution of a copyrighted book just because you compressed it in a ZIP file first.
The problem with your argument is that it is 100% possible to get ChatGPT to produce verbatim extracts of copyrighted works.
Exactly! This is the core of the argument The New York Times made against OpenAI. And I think they are right.
The examples they provided were for very widely distributed stories (i.e. present in the data set many times over). The prompts they used were not provided. How many times they had to prompt was not provided. Their results are very difficult to reproduce, if not impossible, especially on newer models.
I mean, sure, it happens. But it’s not a generalizable problem. You’re not going to get it to regurgitate your Lemmy comment, even if they’ve trained on it. You can’t just go and ask it to write Harry Potter and the goblet of fire for you. It’s not the intended purpose of this technology. I expect it’ll largely be a solved problem in 5-10 years, if not sooner.
I agree. You can’t just dismiss the problem saying it’s “just data represented in vector space” and on the other hand not be able properly censor the models and require AI safety research. If you don’t know exactly what’s going on inside, you also can’t claim that copyright is not being violated.
It honestly blows my mind that people look at a neutral network that’s even capable of recreating short works it was trained on without having access to that text during generation… and choose to focus on IP law.
Right! Like if we could honestly further enhance that feature its an incredible increase in compression tech!
ML techniques have been very useful in compression, yes, but it’s sort of nuts to say that a data structure that encodes only (sometimes overly so for certain regions of its latent space/embedding space/semantics space/whatever you want to call it right now) relationships between values rather than value sequences themselves as storing contiguous copyright protected works is storing partiularized creative works in particularly identifiable manner.
Except that, again, as is literally written in the comment you’re directly replying to, it has been shown that AI can reproduce copyrightable works word for word, showing that it objectively and necessarily is storing particular creative works in a particularly identifiable manner, whether or not that manner is yet known to humans.
It’s called learning, and I wish people did more of it.
You don’t learn by memorizing and reproducing works, you learn by understanding the concepts in various works and producing new works that are combinations of the ideas in those other works. AI doesn’t understand, and it has been shown to be able to reproduce works, so I think it’s fair to say that it’s doing a lot of “memorizing” and therefore plagiarism.
Calling what attention transformers do memorization is wildly inaccurate.
*Unless we’re talking about semantic memory.
Is it though? People memorize things very differently than computers do, but the actual mechanism of storage isn’t particularly important. What’s important is the net result. Whether it uses baysian networks (what we used in class for small-scale NLP), neural networks (what I assume LLMs use), or something else doesn’t particularly matter.
For example, a search engine typically only stores keywords and relationships, so there’s no way for it to reproduce an entire work (ignoring, of course, the “caching” features some search engines have). All it does is associate keywords with source material, so there’s a strong argument that it falls under fair use.
LLMs, on the other hand, process entire works and keep more than just keywords, and they store it in such a way that entire works can be recovered if coaxed. My understanding is that they break up words into something like sets of phonemes, and then queries do a similar break-up as input to the neural network to produce an output, which is then reassembled into text. But that’s my relatively naive understanding of how it all works (I’ve only done university level NLP, and that was years ago), but again, that’s really not the point here. The point is that it uses a lot more of the work than the typical understanding of “fair use,” and if copyrighted works can be reproduced by it, then the copyrighted work is “stored” in some fashion, so it can be thought of as a really complex form of compression, with tricky retrieval mechanisms. So in layman’s terms, it’s “memorizing” entire works in a way not entirely unlike a “mind palace”, and to reproduce a given work, you need the right input to follow the right steps, but a slightly different input will lead to a very different output (i.e. maybe something with similar content, but no copyright violations).
What’s at issue isn’t whether the LLM is likely to reproduce entire works, but whether it can and does, which would mean it’s violating fair use standards.
Learning is not being able to reproduce a news article word for word.
No, it isn’t storing that information in that sequence. What is happening is that it is overly encoding those particular sequential relationships along some arbitrary but tightly mapped semantic concepts represented by dimensions in a massive vector space. It is storing copies of the information on the way that inadvertent copying of music might be based on “memorized” music listened to by the infringing artist in the past.
Not what I said. I used the exact language the above commenter used because it was specific and accurate. Also, inadvertent copyright violation is still copyright violation under US law. I’m not the biggest fan of every application of that law, but the ability to keep large corporations from ripping off small artists and creators is one that I think is good and useful under the global economic system we live under currently.
Yes, inadvertent copying is still copying, but it would be copying in the output and is not evidence of copying happening in the creation of the model. That was why I used the music example, because it is rather probative of where there could be grounds for copyright infringement related to these model architectures. This may not seem an important distinction, but it has significant consequences on who is ultimately liable and how.
The problem with your argument is that it is 100% possible to get ChatGPT to produce verbatim extracts of copyrighted works.
What method still works? I’d like to try it.
I have access to ChatGPT 4, and the latest Anthropic model.
Edit: hm… no answers but downvotes. I wonder why that is.
This would be a good point, if this is what the explicit purpose of the AI was. Which it isn’t. It can quote certain information verbatim despite not containing that data verbatim, through the process of learning, for the same reason we can.
I can ask you to quote famous lines from books all day as well. That doesn’t mean that you knowing those lines means you infringed on copyright. Now, if you were to put those to paper and sell them, you might get a cease and desist or a lawsuit. Therein lies the difference. Your goal would be explicitly to infringe on the specific expression of those words. Any human that would explicitly try to get an AI to produce infringing material… would be infringing. And unknowing infringement… well there are countless court cases where both sides think they did nothing wrong.
You don’t even need AI for that, if you followed the Infinite Monkey Theorem and just happened to stumble upon a work falling under copyright, you still could not sell it even if it was produced by a purely random process.
Another great example is the Mona Lisa. Most people know what it looks like and if they had sufficient talent could mimic it 1:1. However, there are numerous adaptations of the Mona Lisa that are not infringing (by today’s standards), because they transform the work to the point where it’s no longer the original expression, but a re-expression of the same idea. Anything less than that is pretty much completely safe infringement wise.
You’re right though that OpenAI tries to cover their ass by implementing safeguards. Which is to be expected because it’s a legal argument in court that once they became aware of situations they have to take steps to limit harm. They can indeed not prevent it completely, but it’s the effort that counts. Practically none of that kind of moderation is 100% effective. Otherwise we’d live in a pretty good world.
Y’all should really stop expecting people to buy into the analogy between human learning and machine learning i.e. “humans do it, so it’s okay if a computer does it too”. First of all there are vast differences between how humans learn and how machines “learn”, and second, it doesn’t matter anyway because there is lots of legal/moral precedent for not assigning the same rights to machines that are normally assigned to humans (for example, no intellectual property right has been granted to any synthetic media yet that I’m aware of).
That said, I agree that “the model contains a copy of the training data” is not a very good critique–a much stronger one would be to simply note all of the works with a Creative Commons “No Derivatives” license in the training data, since it is hard to argue that the model checkpoint isn’t derived from the training data.
a much stronger one would be to simply note all of the works with a Creative Commons “No Derivatives” license in the training data, since it is hard to argue that the model checkpoint isn’t derived from the training data.
Not really. First of all, creative commons strictly loosens the copyright restrictions on a work. The strongest license is actually no explicit license i.e. “All Rights Reserved.” No derivatives is already included under full, default, copyright.
Second, derivative has a pretty strict legal definition. It’s not enough to say that the derived work was created using a protected work, or even that the derived work couldn’t exist without the protected work. Some examples: create a word cloud of your favorite book, analyze the tone of news article to help you trade stocks, produce an image containing the most prominent color in every frame of a movie, or create a search index of the words found on all websites on the internet. All of that is absolutely allowed under even the strictest of copyright protections.
Statistical analysis of copyrighted materials, as in training AI, easily clears that same bar.
Equating LLMs with compression doesn’t make sense. Model sizes are larger than their training sets. if it requires “hacking” to extract text of sufficient length to break copyright, and the platform is doing everything they can to prevent it, that just makes them like every platform. I can download © material from YouTube (or wherever) all day long.
Model sizes are larger than their training sets
Excuse me, what? You think Huggingface is hosting 100’s of checkpoints each of which are multiples of their training data, which is on the order of terabytes or petabytes in disk space? I don’t know if I agree with the compression argument, myself, but for other reasons–your retort is objectively false.
Just taking GPT 3 as an example, its training set was 45 terabytes, yes. But that set was filtered and processed down to about 570 GB. GPT 3 was only actually trained on that 570 GB. The model itself is about 700 GB. Much of the generalized intelligence of an LLM comes from abstraction to other contexts.
Table 2.2 shows the final mixture of datasets that we used in training. The CommonCrawl data was downloaded from 41 shards of monthly CommonCrawl covering 2016 to 2019, constituting 45TB of compressed plaintext before filtering and 570GB after filtering, roughly equivalent to 400 billion byte-pair-encoded tokens. Language Models are Few-Shot Learners
*Did some more looking, and that model size estimate assumes 32 bit float. It’s actually 16 bit, so the model size is 350GB… technically some compression after all!
They’re absolutely not doing everything they can. Everything they can would be to not use the works. They’re doing as much as they’re willing to do. If it wasn’t for the threat of lawsuits they wouldn’t even be doing that much.
How do you imagine those works are used?
The issue isn’t that you can coax AI into giving away unaltered copyrighted books out of their trunk, the issue is that if you were to open the hood, you’d see that the entire engine is made of unaltered copyrighted books.
All those “anti hacking” measures are just there to obfuscate the fact that that the unaltered works are being in use and recallable at all times.
This is an inaccurate understanding of what’s going on. Under the hood is a neutral network with weights and biases, not a database of copyrighted work. That neutral network was trained on a HEAVILY filtered training set (as mentioned above, 45 terabytes was reduced to 570 GB for GPT3). Getting it to bug out and generate full sections of training data from its neutral network is a fun parlor trick, but you’re not going to use it to pirate a book. People do that the old fashioned way by just adding type:pdf to their common web search.
Again: nobody is complaining that you can make AI spit out their training data because AI is the only source of that training data. That is not the issue and nobody cares about AI as a delivery source of pirated material. The issue is that next to the transformed output, the not-transformed input is being in use in a commercial product.
The issue is that next to the transformed output, the not-transformed input is being in use in a commercial product.
Are you only talking about the word repetition glitch?
Removed by mod
Look… All I have to say is… Support the Internet Archive!
(please)
Heh. Funny that this comment is uncontroversial. The Internet Archive supports Fair Use because, of course, it does.
This is from a position paper explicitly endorsed by the IA:
Based on well-established precedent, the ingestion of copyrighted works to create large language models or other AI training databases generally is a fair use.
By
- Library Copyright Alliance
- American Library Association
- Association of Research Libraries
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages.
Like fuck it is. An LLM “learns” by memorization and by breaking down training data into their component tokens, then calculating the weight between these tokens. This allows it to produce an output that resembles (but may or may not perfectly replicate) its training dataset, but produces no actual understanding or meaning–in other words, there’s no actual intelligence, just really, really fancy fuzzy math.
Meanwhile, a human learns by memorizing training data, but also by parsing the underlying meaning and breaking it down into the underlying concepts, and then by applying and testing those concepts, and mastering them through practice and repetition. Where an LLM would learn “2+2 = 4” by ingesting tens or hundreds of thousands of instances of the string “2+2 = 4” and calculating a strong relationship between the tokens “2+2,” “=,” and “4,” a human child would learn 2+2 = 4 by being given two apple slices, putting them down to another pair of apple slices, and counting the total number of apple slices to see that they now have 4 slices. (And then being given a treat of delicious apple slices.)
Similarly, a human learns to draw by starting with basic shapes, then moving on to anatomy, studying light and shadow, shading, and color theory, all the while applying each new concept to their work, and developing muscle memory to allow them to more easily draw the lines and shapes that they combine to form a whole picture. A human may learn off other peoples’ drawings during the process, but at most they may process a few thousand images. Meanwhile, an LLM learns to “draw” by ingesting millions of images–without obtaining the permission of the person or organization that created those images–and then breaking those images down to their component tokens, and calculating weights between those tokens. There’s about as much similarity between how an LLM “learns” compared to human learning as there is between my cat and my refrigerator.
And YET FUCKING AGAIN, here’s the fucking Google Books argument. To repeat: Google Books used a minimal portion of the copyrighted works, and was not building a service to compete with book publishers. Generative AI is using the ENTIRE COPYRIGHTED WORK for its training set, and is building a service TO DIRECTLY COMPETE WITH THE ORGANIZATIONS WHOSE WORKS THEY ARE USING. They have zero fucking relevance to one another as far as claims of fair use. I am sick and fucking tired of hearing about Google Books.
EDIT: I want to make another point: I’ve commissioned artists for work multiple times, featuring characters that I designed myself. And pretty much every time I have, the art they make for me comes with multiple restrictions: for example, they grant me a license to post it on my own art gallery, and they grant me permission to use portions of the art for non-commercial uses (e.g. cropping a portion out to use as a profile pic or avatar). But they all explicitly forbid me from using the work I commissioned for commercial purposes–in other words, I cannot slap the art I commissioned on a T-shirt and sell it at a convention, or make a mug out of it. If I did so, that artist would be well within their rights to sue the crap out of me, and artists charge several times as much to grant a license for commercial use.
In other words, there is already well-established precedent that even if something is publicly available on the Internet and free to download, there are acceptable and unacceptable use cases, and it’s broadly accepted that using other peoples’ work for commercial use without compensating them is not permitted, even if I directly paid someone to create that work myself.
But they all explicitly forbid me from using the work I commissioned for commercial purposes
I fear the courts will side with the tech companies on this as regardless of how illegal or immoral a certain act is, if you do it on a large enough scale it becomes “okay” again in the eyes of the system. Genocide, large scale fraud, negligent financial actions, pollution/poisoning, etc. You dump toxic chemicals into one person’s cup and you get the book thrown at you. You dump toxic chemicals into an entire city’s water supply and you pay a paltry fine that is never enough to seriously damage the company because that’s bad for the economy.
I recently visited a museum and i really loved it. Getting up close to an image and seeing none of the fuzziness, no AI “shimmer” on photos and every stroke made sense (as in you could see that an arm moved a brush and you could see the path it took etc.). Hands made sense. And while tryptichons were not exactly precise when it comes to the anatomy of humans, no humans had anything smeared etc.
If you put a gazillion monkeys on a typewriter they can write Shakespeare.
If you train one ai for a ton of epochs it can write Shakespeare.
All pure mathematical coincidence.
It was the best of times, it was the BLURST OF TIMES! Stupid monkey!
If you put a gazillion monkeys on a typewriter they can write Shakespeare.
This is a mathematical curiosity borne out of pure randomness. An LLM trained on a dataset to generate similar content is quite the opposite of randomness.
Like fuck it is. An LLM “learns” by memorization and by breaking down training data into their component tokens, then calculating the weight between these tokens.
But this is, at a very basic fundamental level, how biological brains learn. It’s not the whole story, but it is a part of it.
there’s no actual intelligence, just really, really fancy fuzzy math.
You mean sapience or consciousness. Or you could say “human-level intelligence”. But LLM’s by definition have real “actual” intelligence, just not a lot of it.
Edit for the lowest common denominator: I’m suggesting a more accurate way of phrasing the sentence, such as “there’s no actual sapience” or “there’s no actual consciousness”. /end-edit
an LLM would learn “2+2 = 4” by ingesting tens or hundreds of thousands of instances of the string “2+2 = 4” and calculating a strong relationship between the tokens “2+2,” “=,” and “4,”
This isn’t true. At all. There are math specific benchmarks made by experts to specifically test the problem solving and domain specific capabilities of LLM’s. And you can be sure they aren’t “what’s 2 + 2?”
I’m not here to make any claims about the ethics or legality of the training. All I’m commenting on is the science behind LLM’s.
Get a load of this maroon, they think LLMs are actually sapient! Thanks, I needed that laugh.
Get a load of this maroon, they think LLMs are actually sapient!
I guess reading comprehension is as bad here as it’s ever been on the internet.
Fine, you win, I misunderstood. I still disagree with your actual point, however. To me, Intelligence implies the ability to learn in real-time, to adapt to changes in circumstance, and for self-improvement. Once an LLM is trained, it is static and unchanging until you re-train it with new data and update the model. Even if you strip out the sapience/consciousness-related stuff like the ability to think critically about a scenario, proactively make decisions, etc., an LLM is only capable of regurgitating facts and responding to its immediate input. By design, any “learning” it can do is forgotten the instant the session ends.
Fine, you win, I misunderstood.
It’s not a competition, but I genuinely respect you for saying you misunderstood.
Once an LLM is trained, it is static and unchanging until you re-train it with new data and update the model.
Absolutely! I honestly think this is the main thing (or at least one of the main things) that prevent human-level intelligence or even sentience in LLM’s.
Think about how our minds work. From the moment we’re born (really, it’s way before that) our brains are bombarded with input and feedback from every sense. It takes a person many months of that to start recognizing things. That’s also why babies sleep so much, their brains are kinda “training” and growing fast. Organizing all the data into memories.
Side bar: this is actually what dreams are. Dreams are emotions, thoughts, ideas, or whatever concept a neuron or group of neurons are associated with getting triggered. When we dream it’s our brain taking the days inputs and building new connections. The neural connections in our brains are very much like weights and feed-forward process of neural activation is near identical to how artificial neural networks function. They aren’t called “artificial neural networks” for no reason.
Here’s a useful graphic that shows things that make up “intelligence”
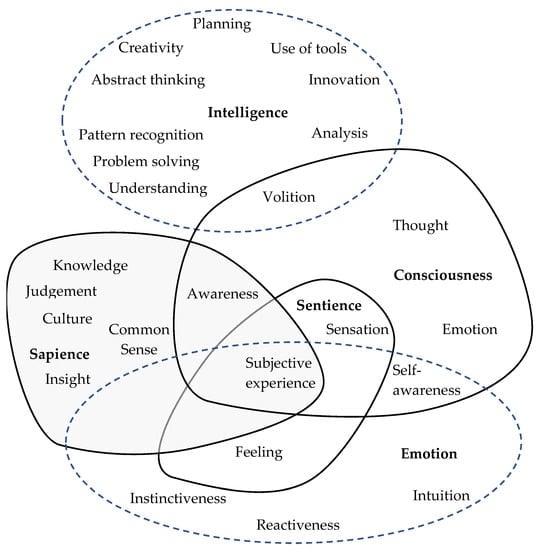
A very basic definition of intelligence is “the ability to solve problems or make decisions”.
I think the term is just often misused in common parlance so often that people start applying in a scientific setting incorrectly. Kinda how people used to call an entire computer the CPU, which like the word intelligence everyone understands what’s being said, but it’s factually wrong.
Same thing today when people say “I bought a new GPU” when they should say “I bought a new video card” as the GPU is just a component.
Bullshit. AI are not human. We shouldn’t treat them as such. AI are not creative. They just regurgitate what they are trained on. We call what it does “learning”, but that doesn’t mean we should elevate what they do to be legally equal to human learning.
It’s this same kind of twisted logic that makes people think Corporations are People.
tweet is good, your body argument is completely wrong
Disagree. These companies are exploiting an unfair power dynamic they created that people can’t say no to, to make an ungodly amount of money for themselves without compensating people whose data they took without telling them. They are not creating a cool creative project that collaboratively comments on or remixes what other people have made, they are seeking to gobble up and render irrelevant everything that they can, for short term greed. That’s not the scenario these laws were made for. AI hurts people who have already been exploited and industries that have already been decimated. Copyright laws were not written with this kind of thing in mind. There are potentially cool and ethical uses for AI models, but open ai and google are just greed machines.
Edited * THRICE because spelling. oof.
deleted by creator
This process is akin to how humans learn…
I’m so fucking sick of people saying that. We have no fucking clue how humans LEARN. Aka gather understanding aka how cognition works or what it truly is. On the contrary we can deduce that it probably isn’t very close to human memory/learning/cognition/sentience (any other buzzword that are stands-ins for things we don’t understand yet), considering human memory is extremely lossy and tends to infer its own bias, as opposed to LLMs that do neither and religiously follow patters to their own fault.
It’s quite literally a text prediction machine that started its life as a translator (and still does amazingly at that task), it just happens to turn out that general human language is a very powerful tool all on its own.
I could go on and on as I usually do on lemmy about AI, but your argument is literally “Neural network is theoretically like the nervous system, therefore human”, I have no faith in getting through to you people.







{kind=link}