well that’s provably false as the neural network can be traced to understand the exact process and calculations that it follows when doing math. See the above research under heading “Mental Math”.
The reason LLMs struggle to count letters is because of tokenization. The text is first converted to tokens, numeric vectors which represents whole words or parts of words, before being given to the LLM, and the LLM has no concept of or access to the underlying letters that make up the words. The LLM outputs only tokens, which are converted back into text.
EDIT: you can downvote me, but facts are facts lol.
There is definitely more going on with LLMs than just direct parroting.
However, there is also an upper limit to what an LLM can logic/calculate. Since LLMs basically boil down to a series of linear operations, there is an upper bound on all of them as to how accurately they can calculate anything.
Most chat systems use python behind the scene for any actual math, but if you run a raw LLM you can see the errors grow faster as you look at higher orders of growth (addition, multiplication, powers, etc.).
Yes, exactly. It can do basic math and also doesn’t really matter because it is really good at interfacing with tools/functions for calculation anyway
However, there is also an upper limit to what an LLM can logic/calculate. Since LLMs basically boil down to a series of linear operations, there is an upper bound on all of them as to how accurately they can calculate anything.
Also this is only true when LLMs are not using Chain of Thought.
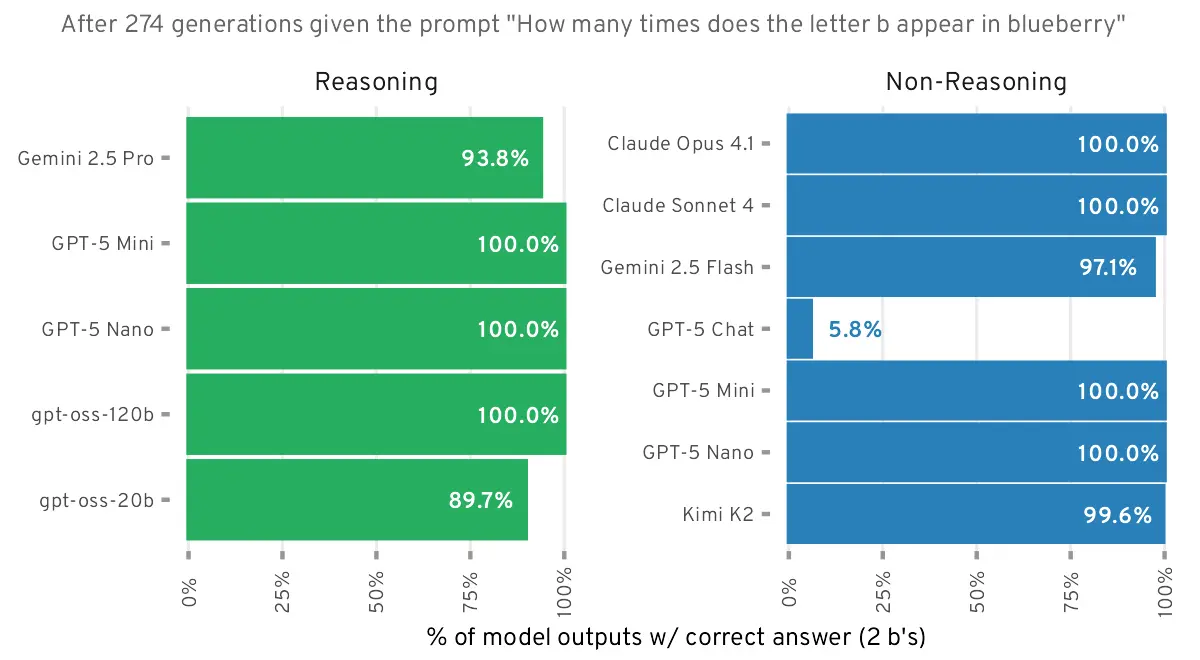
Reading comprehension. The only thing it cannot count are specifically letters of tokenized words. If you separate the letters out into separate tokens (“B L U E B E R R Y”, etc) it will get it correct 100% of the time.
What makes you think that using single letters as tokens instead could teach a stochastic parrot to count or calculate? Both are abilities. You can’t create an ability only from a set of data no matter how much data you have. You can only make a model seem to have that ability.
Yeah, that’s just not how neural networks work…
No math teacher will let students guess the result of an equation.
https://en.wikipedia.org/wiki/Universal_approximation_theoremActual math directly contradicts your beliefs. I know its trendy and you want to feel smarter than people who have spent literally decades researching NNs and staked billions of dollars developing it, but you’re wrong.
Your claim is like claiming that boolean circuits cannot do math because all they do is “true” or “false”.
Just like no LLM will ever be able to understand what complementary colors are. Which is one of my favorite tests because it has a 100 % error rate.
LOL
The funniest part of this is not the fact that an LLM just got 3 for 3 correct, and therefore has a 100% success rate, thus proving you wrong again, but the fact that your “favorite test” would be one that you incorrectly believe “no LLM will ever be able to” do because…
Stop trying to make a screwdriver shoot laser beams, it’s not going to happen.
^ this you??? “My favorite test is to see if the screwdriver shoots laser beams” 🙃
And why didn’t you include the name of the model in your test?
I was using standard RGB hex codes, so I didn’t really need to specify because its the assumed default. If it was something different, I would need to specify. EDIT: oh I just realized you meant the LLM model, not the color model (RYB vs RGB). It was just from ChatGPT, thought the interface would be recognizable enough.
Looks like you don’t want me to try it myself. It would be interesting to do so.
Huh? What do you mean? Go try it!
Of course with values which don’t fit perfectly into 8 bit. What if I define the range from 0 to 47204 for each color channel instead
Yeah, so this is already a thing. 24-bit color (8 bits per color channel) already gives you 16,777,216 colors, which is pretty good, but if you want more precision, you can just use decimal (floating point) numbers for each channel, like sRGB(0.25, 0.5, 1.0) (https://en.wikipedia.org/wiki/SRGB) OR even better would be to use oklch (https://en.wikipedia.org/wiki/Oklab_color_space). This is a solved problem. Or you cold just define your range as 0 to 47204.
So… we’ve gone from “no LLM will ever be able to understand what complementary colors are” to “b-b-but what about arbitrary color models I make up??” And yeah, it will handle those too, you just have to tell it what it is when you prompt it.
Each time I ask any LLM what the complementary color to red is. Then I always get green as answer instead of cyan (With cyan being the only correct answer). And a completely wrong explanation about what complementary colors are based on digital screens.
🤦 Oh… oh wow, I was giving you way more credit than what you actually meant. You do realize there is more than one color model? https://en.wikipedia.org/wiki/Complementary_colors#In_different_color_models You probably should read the explanation about complementary colors based on digital screens that they are providing to you (or just pay attention in elementary art class), because you might actually learn something new.
Red Yellow Blue and Cyan Yellow Magenta are both subtractive color models. RGB is an additive color model.
https://www.anthropic.com/research/tracing-thoughts-language-model
well that’s provably false as the neural network can be traced to understand the exact process and calculations that it follows when doing math. See the above research under heading “Mental Math”.
The reason LLMs struggle to count letters is because of tokenization. The text is first converted to tokens, numeric vectors which represents whole words or parts of words, before being given to the LLM, and the LLM has no concept of or access to the underlying letters that make up the words. The LLM outputs only tokens, which are converted back into text.
EDIT: you can downvote me, but facts are facts lol.
There is definitely more going on with LLMs than just direct parroting.
However, there is also an upper limit to what an LLM can logic/calculate. Since LLMs basically boil down to a series of linear operations, there is an upper bound on all of them as to how accurately they can calculate anything.
Most chat systems use python behind the scene for any actual math, but if you run a raw LLM you can see the errors grow faster as you look at higher orders of growth (addition, multiplication, powers, etc.).
Yes, exactly. It can do basic math and also doesn’t really matter because it is really good at interfacing with tools/functions for calculation anyway
Also this is only true when LLMs are not using Chain of Thought.
So what you’re saying is it can’t count.
Got it.
Reading comprehension. The only thing it cannot count are specifically letters of tokenized words. If you separate the letters out into separate tokens (“B L U E B E R R Y”, etc) it will get it correct 100% of the time.
deleted by creator
Yeah, that’s just not how neural networks work…
https://en.wikipedia.org/wiki/Regression_analysis
You tried.
deleted by creator
https://en.wikipedia.org/wiki/Universal_approximation_theorem Actual math directly contradicts your beliefs. I know its trendy and you want to feel smarter than people who have spent literally decades researching NNs and staked billions of dollars developing it, but you’re wrong.
Your claim is like claiming that boolean circuits cannot do math because all they do is “true” or “false”.
And also, https://en.wikipedia.org/wiki/Recurrent_neural_network#Neural_Turing_machines recurrent neural networks are Turing complete when paired with memory, and therefore can be used to any calculations or computations that a conventional computer can do.
deleted by creator
LOL
The funniest part of this is not the fact that an LLM just got 3 for 3 correct, and therefore has a 100% success rate, thus proving you wrong again, but the fact that your “favorite test” would be one that you incorrectly believe “no LLM will ever be able to” do because…
^ this you??? “My favorite test is to see if the screwdriver shoots laser beams” 🙃
deleted by creator
I was using standard RGB hex codes, so I didn’t really need to specify because its the assumed default. If it was something different, I would need to specify.EDIT: oh I just realized you meant the LLM model, not the color model (RYB vs RGB). It was just from ChatGPT, thought the interface would be recognizable enough.Huh? What do you mean? Go try it!
Yeah, so this is already a thing. 24-bit color (8 bits per color channel) already gives you 16,777,216 colors, which is pretty good, but if you want more precision, you can just use decimal (floating point) numbers for each channel, like sRGB(0.25, 0.5, 1.0) (https://en.wikipedia.org/wiki/SRGB) OR even better would be to use oklch (https://en.wikipedia.org/wiki/Oklab_color_space). This is a solved problem. Or you cold just define your range as 0 to 47204.
So… we’ve gone from “no LLM will ever be able to understand what complementary colors are” to “b-b-but what about arbitrary color models I make up??” And yeah, it will handle those too, you just have to tell it what it is when you prompt it.
deleted by creator
🤦 Oh… oh wow, I was giving you way more credit than what you actually meant. You do realize there is more than one color model? https://en.wikipedia.org/wiki/Complementary_colors#In_different_color_models You probably should read the explanation about complementary colors based on digital screens that they are providing to you (or just pay attention in elementary art class), because you might actually learn something new.
Red Yellow Blue and Cyan Yellow Magenta are both subtractive color models. RGB is an additive color model.
https://en.wikipedia.org/wiki/RYB_color_model
Try giving the LLM the hex color code and the color model you’re using that code in, and it will give you the correct complementary color.