Why does OpenAI need to crawl your site more than once? Unless its fetching search results for some question, can’t they just copy it into their training archive, and be done?
Based on tiny bits of insider nuggets and some outside views, I’m increasingly convinced that these huge AI houses are efficiency shitshows. They do not care about internal overutilization, they don’t optimize or check for rogue bots and bugs. They literally run busywork to keep the appearance of busy GPUs. And it’s going to catch up to them when the Chinese models have the same capabilities, and run on peanuts.
All I can tell you is that my server was hammered by a couple of IP addresses. When I did a lookup they were ALL openai and they just would not stop. Until I added protection that is. Then they got bogged down and eventually stopped.
Ive heard talk that their engineers said they dont need to abide by robots.txt since they are not an indexer like google. Which is BS.
I think ultimately copying the data would require having as many hard drives as the entire internet, but repeated queries only requires live bandwidth and minimal storage. One costs OpenAI more, one costs everyone else more.
The “entire internet” is not even that big these days. The Internet Archive, for instance, is on the order of 100s of petabytes. 10K (or at least less than 100K) spinning disks is almost trivial for Azure, who has many millions deployed.
And the actual training runs for text models are in the trillions of tokens; again, chump change data wise.
On the other hand, they’d lose a ton of ephemeral data scraping for training runs every time instead of just saving the good stuff. I suppose it’s possible they mass rescrape and filter the content redundantly, but… that seems like a colossal waste?
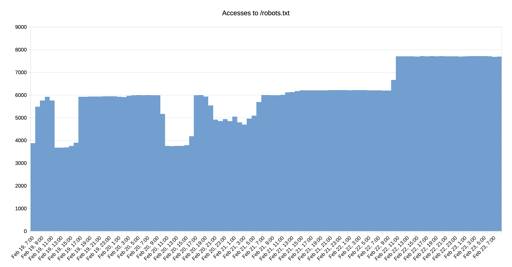
That’s so bizzare to me.
Why does OpenAI need to crawl your site more than once? Unless its fetching search results for some question, can’t they just copy it into their training archive, and be done?
Based on tiny bits of insider nuggets and some outside views, I’m increasingly convinced that these huge AI houses are efficiency shitshows. They do not care about internal overutilization, they don’t optimize or check for rogue bots and bugs. They literally run busywork to keep the appearance of busy GPUs. And it’s going to catch up to them when the Chinese models have the same capabilities, and run on peanuts.
Im not sure. I agree with you.
All I can tell you is that my server was hammered by a couple of IP addresses. When I did a lookup they were ALL openai and they just would not stop. Until I added protection that is. Then they got bogged down and eventually stopped.
Ive heard talk that their engineers said they dont need to abide by robots.txt since they are not an indexer like google. Which is BS.
I think ultimately copying the data would require having as many hard drives as the entire internet, but repeated queries only requires live bandwidth and minimal storage. One costs OpenAI more, one costs everyone else more.
The “entire internet” is not even that big these days. The Internet Archive, for instance, is on the order of 100s of petabytes. 10K (or at least less than 100K) spinning disks is almost trivial for Azure, who has many millions deployed.
And the actual training runs for text models are in the trillions of tokens; again, chump change data wise.
On the other hand, they’d lose a ton of ephemeral data scraping for training runs every time instead of just saving the good stuff. I suppose it’s possible they mass rescrape and filter the content redundantly, but… that seems like a colossal waste?
Hmm, could be what they do, I guess.