There are a couple I have in mind. Like many techies, I am a huge fan of RSS for content distribution and XMPP for federated communication.
The really niche one I like is S-expressions as a data format and configuration in place of json, yaml, toml, etc.
I am a big fan of Plaintext formats, although I wish markdown had a few more features like tables.
It’s completely bonkers that JPEG-XL is as good as it is and no one wants to actually implement it into web browsers
Adobe is backing the format, Apple support is coming along, and there are rumors that Apple is switching from HEIC to JPEG XL as a capture format as early as the iPhone 16 coming out in a few weeks. As soon as we have a full blown workflow that can take images from camera to post processing to publishing in JXL, we might see a pretty strong push for adoption at the user side (browsers, websites, chat programs, social media apps and sites, etc.).
Do you know QOI format ? I would appreciate your opinion about it.
QOI is just a format that’s easy for a programmer to get their head around.
It’s not designed for everyday use and hardware optimization like jpeg-xl is.
You’re most likely to see QOI in homebrewed game engines.
What’s so good about it?
- Existing JPEG files (which are the vast, vast majority of images currently on the web and in people’s own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there’s benefits to adoption, if nothing else for archival and serving old stuff.
- JPEG XL encoding and decoding is much, much faster than pretty much any other format.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
- The format anticipates being useful for both screen and prints. Webp, HEIF, and AVIF are all optimized for screen resolutions, and fail at truly high resolution uses appropriate for prints. The JPEG XL format isn’t ready to replace camera RAW files, but there’s room in the spec to accommodate that use case, too.
It’s great and should be adopted everywhere, to replace every raster format from JPEG photographs to animated GIFs (or the more modern live photos format with full color depth in moving pictures) to PNGs to scanned TIFFs with zero compression/loss.
Existing JPEG files (which are the vast, vast majority of images currently on the web and in people’s own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there’s benefits to adoption, if nothing else for archival and serving old stuff.
Funny thing is, there was talk on the Chrome bug tracker of using just this ability transparently at the HTTP layer (like gzip/brotli compression), but they’re so set on pushing their AVIF format that they backed away from it.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
Someone made a fair point that having a format being both lossy and lossless is not necessarily a great idea. If you download a jpeg file you know it will be compressed, if you download png it will be lossless. Shifting through jxl files to check if it’s lossy or not doesn’t sound very fun.
All in all I’m a big supporter of jxl though, it’s one of the only github repos I actively follow.
Functionally speaking, I don’t see this as a significant issue.
JPEG quality settings can run a pretty wide gamut, and obviously wouldn’t be immediately apparent without viewing the file and analyzing the metadata. But if we’re looking at metadata, JPEG XL reports that stuff, too.
Of course, the metadata might only report the most recent conversion, but that’s still a problem with all image formats, where conversion between GIF/PNG/JPG, or even edits to JPGs, would likely create lots of artifacts even if the last step happens to be lossless.
You’re right that we should ensure that the metadata does accurately describe whether an image has ever been encoded in a lossy manner, though. It’s especially important for things like medical scans where every pixel matters, and needs to be trusted as coming from the sensor rather than an artifact of the encoding process, to eliminate some types of error. That’s why I’m hopeful that a full JXL based workflow for those images will preserve the details when necessary, and give fewer opportunities for that type of silent/unknown loss of data to occur.
ISO 8601 date format. Not because it’s from a standards body, but because it’s simple, sensible, clearly defined, easy to recognize, and very effective.
Date field placement in any order other than most-significant-digits-first is not only counterintuitive, but needlessly complicated to work with. Omitting critical information like the century is ambiguous and confusing.
We don’t live in isolated villages any more. Mixing and matching those problems by accepting all the world’s various regional and personal date styles, especially with no reliable indication of which ones apply in any given case, leads to the hodgepodge of error-prone date madness that we have today.
The 2024-09-02 format should be taught in schools and required in official documents. Let the antiquated date styles fall into disuse outside of art and personal correspondence, like cursive writing.
And it can be sorted alphabetically in all software. That’s a pretty big advantage when handling files on a computer
I wish standards were always open access. Not behind a 600 dollar paywall.
When it is paywalled I’m irritated it’s even called a standard.
DP >> HDMI
The metric system, f*ck the imperial system. Every scientist sticks to the metric system, and why are people even still having an imperial system, with outdated measurements like stones for weight blows my mind.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that, we don’t need another hard to convert temperature measurement.
You are allowed to say fuck here.
I’ll fight you on fahrenheit. It’s very good for weather reporting. 0° being “very cold” and 100° being “very hot” is intuitive.
0° being “very cold” and 100° being “very hot” is intuitive.
As someone who’s not used to Fahrenheit I can tell you there’s nothing intuitive about it. How cold is “very cold” exactly? How hot is “very hot” exactly? Without clear references all the numbers in between are meaningless, which is exactly how I perceive any number in Fahrenfeit. Intuitive means that without knowing I should have an intuitive perception, but really there’s nothing to go on. I guess from your description 50°F should mean it’s comfortable? Does that mean I can go out in shorts and a t-shirt? It all seems guesswork.
About the only useful thing I see is that 100 Fahrenheit is about body temperature. Yeah, that’s about the only nice thing I can say about Fahrenheit. All temperature scales are arbitrary, but since our environment is full of water, one tied to the phase changes of water around the atmospheric pressure the vast majority of people experience just makes more sense.
All temperature scales are arbitrary, but since our environment is full of water, one tied to the phase changes of water around the atmospheric pressure the vast majority of people experience just makes more sense.
But when it comes to weather, the boiling point of water is not a meaningful point of reference.
I suppose I’m biased since I grew up in an area where 0-100°F was roughly the actual temperature range over the course of a year. It was newsworthy when we dropped below zero or rose above 100. It was a scale everybody understood intuitively because it aligned with our lived experience.
But when it comes to weather, the boiling point of water is not a meaningful point of reference.
Well, the freezing point of water is very relevant for weather. If I see that the forecast is -1 degC when it was positive before, I know I will have to watch out for ice on roads.
And the boiling point as the other reference point makes complete sense.
For traffic Celsius is more intuitive since temps approaching zero means slippery roads.
You’re long passed that with Fahrenheit. And on a scale from 0 very cold to 100 very hot, 32 doesn’t seem that cold. Until you see the snow outside.
32 isn’t that cold, even if it’s snowing. I do currently live in Minnesota though, so my sense of temperature is much different than someone from somewhere warm.
Minnesotan here. Can confirm that 32 is still long-sleeve shirt weather.
I regularly see people here walking into a store from the parking lot in T-shirts, in 32° weather. Wind chill makes a far greater difference. 38° from wind chill is far colder than 32° with no wind.
my sense of temperature is much different than someone from somewhere warm
That’s probably the reason for this preference.
10°C for me means my PC doesn’t heat up the room enough and I need a heater. 32°F and I will be shoving my feet in the heater.
Imperial is used in thermodynamics industries because the calculations work out better.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that,
Who is Kalvin? Did you mean kelvin?
One drawback of celsius/centigrade is that its degrees are so coarse that weather reports / ambient temperature readings end up either inaccurate or complicated by floating point numbers. I’m on board with using it, but I won’t pretend it’s strictly superior.
A degree Celsius is not coarse and does not require decimals in weather reports, and I suspect only a person who has never lived in a Celsius-using country could make such silly claims.
IRC.
Jabber.
IPFS.
Yes and RSS feeds.
I also pick this guy’s IRC
Zigbee or really any Bluetooth alternative.
Bluetooth is a poorly engineered protocol. It jumps around the spectrum while transmitting, which makes it difficult and power intensive for bluetooth receivers to track.
IPv6. Stop engineering IoT junk on single-stack IPv4, you dipshits.
Ogg Opus. It’s superior to everything in every way. It’s free and there is absolutely no reason to not support it. It blows my mind that MPEG 1.0 Layer III is still so dominant.
It blows my mind that MPEG 1.0 Layer III is still so dominant.
Count the number of devices in use today that will never support Opus, and it might not blow your mind any longer. Also, AFAIK, the reference implementation still doesn’t implement full functionality on hardware that lacks a floating point unit.
These things take time.
I remember using Xiph’s integer implementation of Ogg Vorbis on my Nokia N-Gage (Symbian S60). I wonder if it’s not a priority for Opus. IIRC, Opus is floats all the way down.
update: it exists.
https://wiki.xiph.org/OpusFAQ#Is_there_a_fixed-point_implementation?
I remember trying to understand Vorbis fixed point codebase, it was completely bonkers, the three of us on this task couldn’t even draw a rough control flow diagram.
I’ll give my usual contribution to RSS feed discourse, which is that, news flash! RSS feeds support video!
It drives me crazy when podcasters are like, “thanks for listening to our audio podcasts. We also have a video feed for our YouTube subscribers.” Just let me have the video in PocketCasts please!
I just wrote a YouTube scraper and exported to RSS and into my podcast client. Using YouTube any other way is masochism in comparison.
I’d like something akin to XML DOM for config files, but not XML.
The one benefit of binary config (like the Windows Registry) is that you can make a change programmatically without too many hoops. With text files, you have a couple of choices for programmatic changes:
- Don’t
- Parse it, make the change, and rewrite it (clobbering comments and whitespace that the user setup; IIRC, npm does this)
- Have some kind of block that says “things below this line were automatically set and shouldn’t be touched” (Klipper does this)
- Have a parser that understands the whole structure, including whitespace and comments, and provides an interface for modifying things in place without changing anything around it (XML DOM)
That last one probably exists for very specific formats for very specific languages, but it’s not common. It’s a little more cumbersome to use as a programmer–anyone who has worked with XML DOM will attest to that–but it’s a lot nicer for end users.
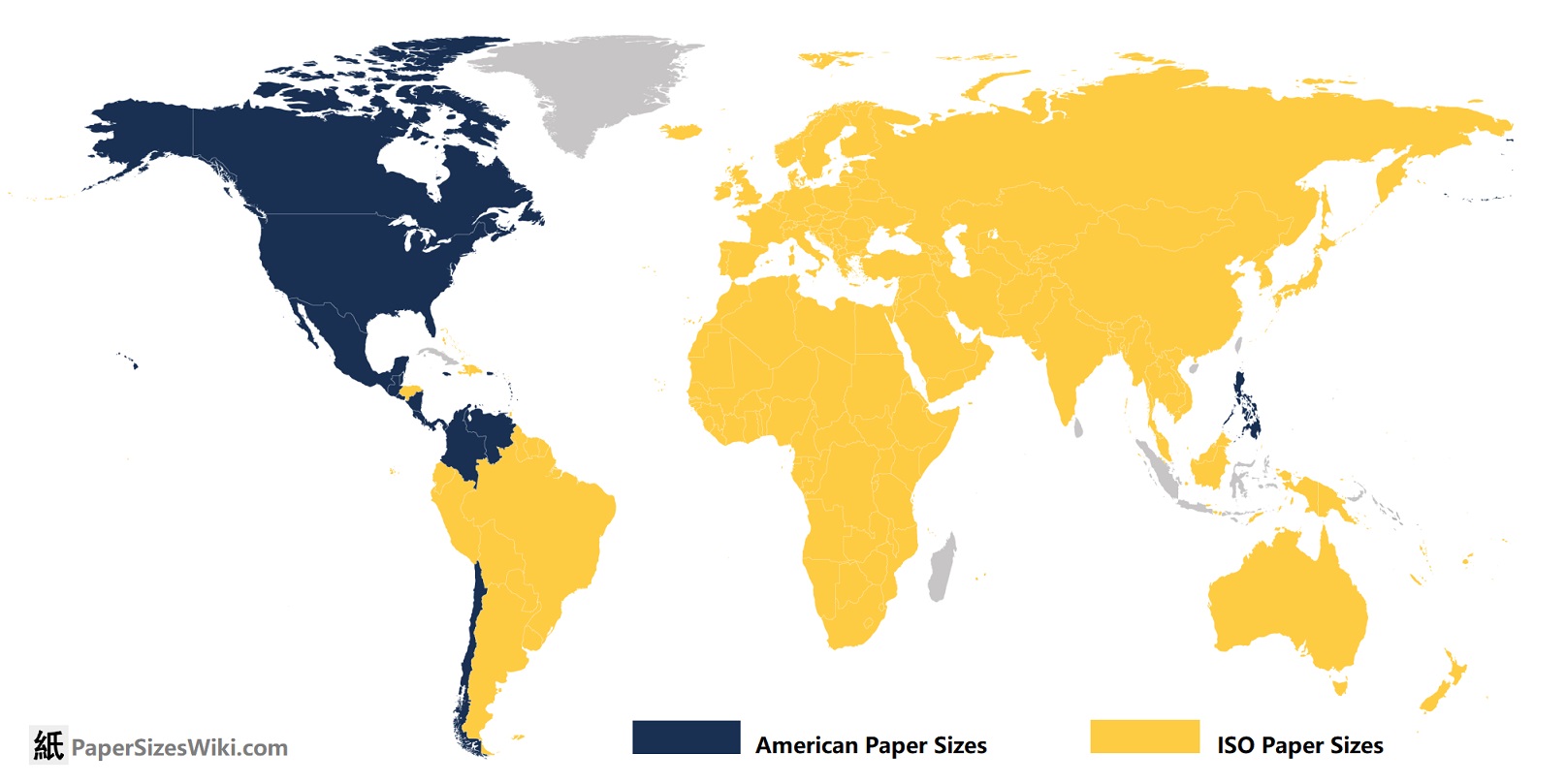
ISO 216 paper sizes work like this: https://www.printed.com/blog/paper-size-guide/
It’s so fucking neat and intuitive! How is it not used more???
sorry to tell you this bud…
The term open-standard does not cut it. People should start using “publicly available and sharable” instead (maybe there is a better name for it).
ISO standards for example are technically “open”. But how relevant is that to a curious individual developer when anything you need to implement would require access to multiple “open” standards, each coming with a (monetary) price, with some extra shenanigans [archived] on top.
IETF standards however are actually truly open, as in publicly available and sharable.
PGP or GPG, however you spell it. You can encrypt stuff, protect your email from prying eyes!
Also FOSS in general.
I don’t use XMPP but it seems like such a no-brainer
Not matrix? XMPP is a good idea, but the wildly different levels of support among clients cause problems even back in its heyday Matrix solves some of that, fully encrypted, chat history stored on the server in encrypted form, supports gateways to other services.
Definitely not matrix.
Those problems you speak of about XMPP are not really a concern anymore and haven’t been for a while.
Matrix on the other hand is very difficult to implement, and currently there’s only one (maybe two?) viable implementation choices. It is way over complicated, resource intensive, and has privacy issues.
Does it have privacy issues compared to XMPP which doesn’t enforce the privacy extensions? I figure they are about the same there. Asking genuinely as I do not know other than Matrix might leak some metadata.
And quite frankly, I really wish we’d just agree on one or the other. Would love to host an instance and move some people to it but both are just stuck in this quasi-half used/half not state. And even people on here can’t agree what should be “standard.”
Xmpp definitely wins in privacy. What is there to privacy more than message content and metadata? Matrix definitely fails the second one, and is E2E still an issue for public groups? I don’t remember if they fixed that.
XMPP being a protocol built for extensibility means it will be hard for it not to keep up with times.
On your point of picking one or the other, I’d say pick the one you like and bridges will help you connect to the other. But XMPP came way before matrix, and I believe they fractured the community instead of building it.
There’s a good reason all the big techs built on top of xmpp (meta, Google, etc). It’s a very good protocol and satisfies modern demands very well.
Xmpp definitely wins in privacy. What is there to privacy more than message content and metadata? Matrix definitely fails the second one, and is E2E still an issue for public groups? I don’t remember if they fixed that.
XMPP being a protocol built for extensibility means it will be hard for it not to keep up with times.
Okay so how does modern XMPP protect this? When I last used XMPP, some (not all) clients supported OTR-IM, a protocol for end to end encryption. And there wasn’t a function for server stored chat history (either encrypted or plaintext).
Have these issues been fixed?It’s not perfect yet, but it’s much, much better than the old days.
OMEMO is supported by every major client, and they interoperate successfully. Unfortunately, most clients are stuck with an older version of the OMEMO spec. It’s not ideal, but it doesn’t cause any practical issue, unless you use Kaidan or UWPX, which only support the latest version.
All popular clients and servers support retrieving chat history now too.
In practice, I’ve been using it for several months to chat with friends and family, and haven’t had any issues.
Honestly I just haven’t looked at Matrix yet. Unfortunately like many of the privacy-centric protocols it’s mostly used by people trying to hide something.
This is really not accurate. Matrix is not designed to be a super privacy first protocol. It’s like Lemmy in the it’s designed to solve a problem and be a useful federated collaboration tool. It borrows features from a number of popular messaging platforms. Message history is stored on the server but encrypted client side so privacy is preserved. It supports group chat rooms. It supports voice and video. And most importantly, it supports bridges- you can connect your matrix to other services that are completely incompatible with matrix using a bridge. Perhaps the best example of this is Beeper, which is built on matrix. They are trying to replicate the user experience of the old app Trillian- beeper can link with a number of chat services including Google messages, slack, WhatsApp, telegram, signal, etc. Thus you get all your chats in one place.
I feel like I would enjoy Beeper but I just cannot get past the name
What’s wrong with Beeper?
Nothing objectively, it just sounds so stupid to me that I have an irrational aversion lmao
(This is not an insult, I just had a realization that I think might affect you)-- do you know what the name comes from?
Years ago there was a thing called a beeper before everyone had cell phones. It was a one way paging system-- you’d give your friends your beeper number, they’d call it, type in their phone number, and their number (or whatever they dialed in) would appear on your beeper. You’d then use a landline phone to call them back (early versions of the system had no text or reply capability, only numbers and only one-way).
I always thought it was a cool name. But thinking about it I realize someone less than maybe 25-30 years old might literally have never encountered such a device. Much like a 5.25" floppy disk or rotary dial phone, they went out of style years ago and a young person might never have encountered one.
Curious if that’s you?
The semantic web and social linked data. We could have applications share data without depending on big tech, but rather based on application standards.
It can be used today and gains traction but I wouldn’t mind it going faster. Especially the interoperable personal app space could use some love and attention.
Like with the Solid Project ?
Exactly. The Semantic Web is broader than Solid but Solid is great for personal apps.
Say you buy a smartphone. The specifications of the smartphone likely belong elsewhere than in a Solid Personal Online Datastore, but they can be pulled in from semantic data on the product website. Your own proof of purchase is a great candidate for a Solid POD, as is the trace of any repairs made to it.
These technologies are great to cross the barriers between applications. If we’d embrace this, it would be trivial to find the screen protector matching your exact smartphone because we’d have an identifier to discover its type and specifications. Heck, any product search would be easier if you could combine sources and compare with what you already have.
The sharing tech exists. Building apps works also. Interpreting the information without building a dedicated interface seems lacking for laymen.
GRPC for building APIs instead of REST. Type safety makes life easier
The biggest problems with gRPC are:
- Very complicated. Way more complexity than you want in most cases.
- Depends on HTTP 2. I’ve seen people who weren’t even doing web stuff reach for gRPC, and now boom you have a web server in your stack for now reason. Compare to Thrift which properly separates out encodings, transports, etc.
- Doesn’t work from the web. There are actually two modifications to gRPC to make it work on the web which means you have three different incompatible versions of gRPC with different feature sets. IIRC some of them require setting up complex proxies, some don’t support streaming calls, ugh. Total mess.
Plain HTTP can be type safe. Just publish JSON schema or Typespec files or even use Protobuf.