
But if you’re the Internet Archive, fuck you its lawsuit time. I hate this cyberpunk present.
The Internet Archive does not create shareholder value
/s
Then it sounds like your business is a failure and should be shutdown.
WHO is the one guy who downvotes you???
“NO! UNPROFITABLE BUSINESSES DESERVE TO THRIVE!!! MUST FEED THE BILLIONAIRES!!!”
Maybe OpenAI learned to downvote…
deleted by creator
Downvoting for the use of an uncommon word.
Supercalifragalisticexpialidocuious
Edit: 10 people here didn’t grow up with Mary Poppins…
Sound was quite atrocious, downvoted 👎
I think people are missing the joke here 😄
Venn diagram of Lemmy users and Mary Poppins stans barely touching.
You spelled it wrong you brick.
You could even say his spelling is quite atrocious
Lmao the down votes on this are really funny to me
Just imagine baron bomburst and the child catcher furiously downvoting this comment lol
What I get a kick out of is the down and upvotes mean basically nothing and yet people still get super sensitive about them. They only move your comment up or down the thread. It’s not like reddit where there is a karma count for all your posts and comments. Hell you don’t even get auto hidden like the way reddit would do. You just get downvoted.
Some people downvote to show disapproval. Others downvote if the comment doesn’t add to the conversation. Still others are just trolling. No one should worry about the downvotes.
See I look at it differently.
An upvote means:
You’re the coolest person that’s ever lived, and I’m desperate for you to put your baby in me, even if that’s not biologically possible! You should be supreme ultimate being of the universe, and all shall cherish your existence until the end of time!
And a downvote means:
You sack of shit! You human garbage! Nobody loves you. Everyone hates you. The world has a better time when you’re not around, you waste of human skin! Your parents should have used a condom, and the world regrets they didn’t every day. Go live under a bridge, homeless, dirty, and alone, you genetic waste of space.
anodyne
anodyne /ăn′ə-dīn″/ adjective
- Capable of soothing or eliminating pain.
- Relaxing. “anodyne novels about country life.”
- Serving to assuage pain; soothing.
tanks fer noo werd dae fren
I always figure it’s someone whose life has become so pathetic, they bitterly downvote every single comment to try feel some control. And as a result, they feel like the Phantom of the Socials. Alone, but the true master of the place.
“Everyone must wonder, ‘Who keeps downvoting us?’ It is I! The true Master of Lemmy and- No, mother!.. Yes, mother!.. I tried but nobody wants to talk to me!.. I don’t want to!.. Yeah, she’s cute!.. I don’t want you to do that!.. Mother put the phone down!”
Lol how about every pirate who fundamentally opposes the copyright system?
How about everyone who uses Google and doesn’t want to see it shut down for scraping copyrighted content to provide a search engine?
Seriously, explain to me what’s different at a fundamental level about OpenAI scraping the web and transforming the data through an LLM and Google scraping the web and transforming the data through their algorithms (which include LLMs)?
Google (used to) scrapes the specific details authorized by robots.txt and uses it to make your content visible.
OpenAI scrapes everything it can technically see, ignoring robots.txt and feeds i to a black box and regurgitates it claiming it’s something new, that it deserves to be paid for.
Quite different actually.
So if OpenAI complies with Robots.txt files then there’s no issue right?
Because then they’re identical. Open AI spent a bunch of money building a powerful system they feed those results to, as did Google.
I dont see why why being downvoted you make some very good points.
Id actually like to see google shut down on copyright grounds. The innovation of necessity would drive foss search alternatives that just ignore said restrictions and most likly we would end up with a better product.
I appreciate the defense of the blind downvotes, though I can’t say I necessarily see how Foss search engines would even be allowed to exist in that case?
There is a difference between allowed and what people do. Piracy isnt allowed u can still pirate literally anything if u want to tho.
You’d probably end up back with AI at that point. A lot easier to distribute a trained model then an entire web index.
Yep but at least the weights would be free
If not, The Pirate Bay would like a word.
I’d love to see how scared some big companies would be if we could decriminalize piracy
Well alright then, that means you have the wrong business model, sucks to be you, NEXT.
“because it’s supposedly “impossible” for the company to train its artificial intelligence models — and continue growing its multi-billion-dollar-business — without them.”
O no! Poor richs cant get more rich fast enough :(
And I can’t eat without shoplifting…
I didn’t see anything
Bet they get the pass that the Internet Archive didn’t.
But I NEED to break the law.
Well, alright then. As long as it’s for business.
Idk, usually people shut down their business if it can’t make a profit…
“I loose money when I pay for Netflix.”
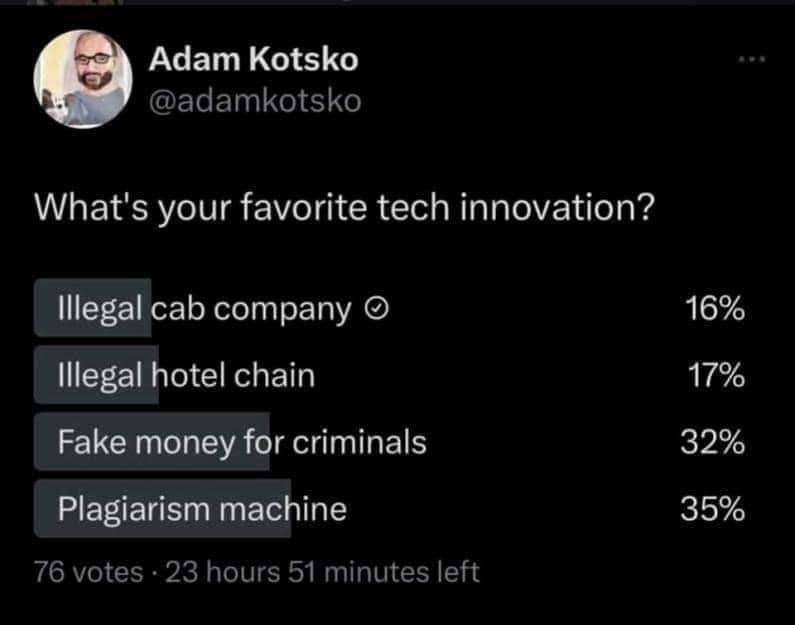
Honestly this meme is way understating the sinisterness
- Election interference for money machine
- Whole internet is ads company
- Dopamine addiction for all children
- Superpowers for law enforcement
What irks me most about this claim from OpenAI and others in the AI industry is that it’s not based on any real evidence. Nobody has tested the counterfactual approach he claims wouldn’t work, yet the experiments that came closest–the first StarCoder LLM and the CommonCanvas text-to-image model–suggest that, in fact, it would have been possible to produce something very nearly as useful, and in some ways better, with a more restrained training data curation approach than scraping outbound Reddit links.
All that aside, copyright clearly isn’t the right framework for understanding why what OpenAI does bothers people so much. It’s really about “data dignity”, which is a relatively new moral principle not yet protected by any single law. Most people feel that they should have control over what data is gathered about their activities online, as well as what is done with those data after it’s been collected, and even if they publish or post something under a Creative Commons license that permits derived uses of their work, they’ll still get upset if it’s used as an input to machine learning. This is true even if the generative models thereby created are not created for commercial reasons, but only for personal or educational purposes that clearly constitute fair use. I’m not saying that OpenAI’s use of copyrighted work is fair, I’m just saying that even in cases where the use is clearly fair, there’s still a perceived moral injury, so I don’t think it’s wise to lean too heavily on copyright law if we want to find a path forward that feels just.
“data dignity”,
Apparently, this is about creating a new kind of intellectual property; a generalized and hypercharged version of copyright that applies to all sorts of data.
Maybe, this is a touchy subject, but to me this seems like an extremely right wing approach. Turn anything into property and the magic market will turn everything into rainbows and unicorns. Maybe you feel different about this?
Regardless of classification, such a policy is obviously devastating to society. Of course, your argument does not consider society but only the feelings of some individuals. Feelings are valid but one has to consider the effect of such a policy, too. Not every impulse should be given power. This is especially true where such feelings are strongly influenced by culture and circumstance. For example, people in the US and the UK have -on the whole - rather different feelings on being ruled by a king. I don’t feel that I should be able to control what other people do with data, maybe because I’m a bit older and was socialized into that whole information-wants-to-be-free culture. I don’t even remember having a libertarian phase.
How would you pitch this to me?
I’m not proposing anything new, and I’m not here to “pitch” anything to you–read Jaron Lanier’s writings e.g. “Who Owns the Future”, or watch a talk/interview given by him, if you’re interested in a sales pitch for why data dignity is a problem worth addressing. I admire him greatly and agree with many of his observations but am not sure about his proposed solution (mainly a system of micro-payments to creators of the data used by tech companies)–I’m just here to point out that copyright infringement isn’t in fact, the main nor the only thing that is bothering so many people about generative AI, so settling copyright disputes isn’t going to stop all those people from being upset about it.
As to your comments about “feelings”, I would turn it around to you and ask why it is important to society that we prioritize the feelings (mainly greed) of the few tech executives and engineers who think that they will profit from such practices over the many, many people who object to them?
And have you stopped beating your wife yet?
Asking loaded questions isn’t the big brain move you think. It’s just dishonest.
@General_Effort @mm_maybe
Maybe this will finally be the push we, as a society, need to realize that “intellectual property” is a legal fiction that we are all better off without?Yeah, I would agree that there’s something really off about the framework that just doesn’t fit most people’s feelings of justice or injustice. A synth YouTuber, of all people, made a video about this that I liked, though his proposed solution is about as workable as Jaron Lanier’s: https://youtu.be/PJSTFzhs1O4?si=ZvY9yfOuIJI7CVUk
Again, I don’t have a proposal of my own, I’ve just decided for myself that if I’m going to do anything money-making with LLMs in my practice as a professional data scientist, I’ll rely on StarCoder as my base model instead of the others, particularly because a lot of my clients are in the public sector and face public scrutiny.
This has all been tested and is being continuously retested. Start here, for example: https://en.wikipedia.org/wiki/Neural_scaling_law
I know, on lemmy you will get the impression that engineers and scientists are all just bumbling fools who are intellectually outclassed by any high schooler with internet access. But how likely is that, really?
Scaling laws are disputed, but if an effort has in fact already been undertaken to train a general purpose LLM using only permissively-licensed data, great! Can you send me the checkpoint on Huggingface, a github page hosting relevant code, or even a paper or blog post about it? I’ve been looking and hadn’t found anything like that yet.
Scaling laws are disputed
Not in general.
There is not enough permissively licensed text to train models of any size, and what there is, lacks in diversity. Wikipedia, government documents, stack overflow, century old stuff, … An LLM trained on that is not likely to be called “general purpose”, because scaling laws. Sometimes such small models are trained for research purposes but I don’t have a link ready. They are not something you’d actually use. Perhaps you could look at Microsoft’s Phi series of models. They are trained on synthetic data, though that’s probably not what you are looking for.
yes, I’ve extensively written about Phi and other related issues in a blog post which I’ll share here: https://medium.com/@matthewmaybe/data-dignity-is-difficult-64ba41ee9150
then perish
If I was exempt from copyright, I too could easily make oodles of money
How do you like my new song? I call it “while my guitar gently weeps” , a real banger. the B side is a little holiday ditty I put together all by myself called “White Christmas” .
So…. not a legitimate business then.
If they get this, I’m gonna make s fortune ripping the copyright protection off stuff so that I can sell products as my own.
Yeah! I can’t make money running my restaurant if I have to pay for the ingredients, so I should be allowed to steal them. How else can I make money??
Alternatively:
OpenAI is no different from pirate streaming sites in this regard (loosely: streaming sites are way more useful to humanity). If OpenAI gets a pass, so should every site that’s been shut down for piracy.
deleted by creator
Piracy steals from the rich and gives to the poor. ChatGPT steals from the rich and the poor and keeps for itself.















